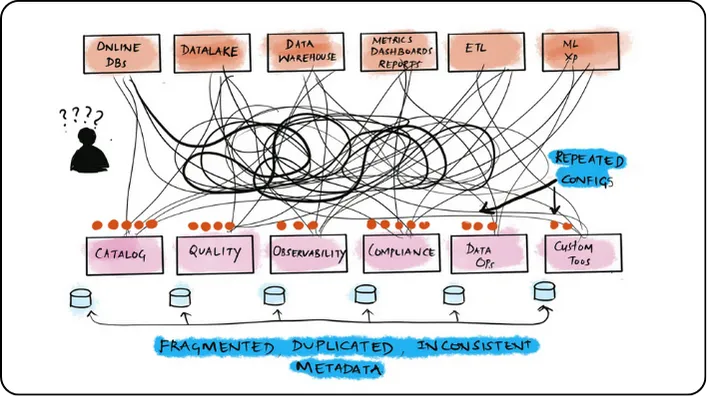
Từ Google Sheet đến Wiki.JS, và giờ là… Data Catalog?
Thuở sơ khai, khi Data Platform còn là một “cổ máy nghiền dữ liệu” thô sơ, việc quản lý thông tin dữ liệu không mấy phức tạp. Chúng tôi - những Data Engineer - trung thành với “Google Sheet” như một giải pháp quản lý thông tin dữ liệu. Mọi thứ đều rõ ràng, dễ tìm, vì dữ liệu và pipeline còn ít.
Nhưng thời gian trôi qua, “cỗ máy” Data Platform ngày càng phình to, dữ liệu cũng theo đó mà tăng lên chóng mặt. Google Sheet dần trở nên quá tải. Chúng tôi chuyển sang “Wiki.JS” với khả năng tìm kiếm ưu việt, hy vọng giải quyết được bài toán quản lý thông tin ngày càng phức tạp.
Tuy nhiên, thử thách mới lại đến. Khách hàng của chúng tôi - các phòng ban Marketing, Product Owner, Finance… - ngày càng phụ thuộc vào dữ liệu trên Dashboard. Họ liên tục đặt câu hỏi về nguồn gốc, cách tính của các metric. Với số lượng Dashboard ngày càng tăng, việc “lục tìm” thông tin trở thành cơn ác mộng. Chúng tôi phải “trace” lại từng bước xử lý, đôi khi phải “đào” sâu vào source code, tiêu tốn nhiều thời gian.
Liệu có giải pháp nào tối ưu hơn không? Chẳng lẽ phải viết document chi tiết cho từng bước xử lý?
Sau một thời gian tìm hiểu, cụm từ “Data Catalog” xuất hiện như một tia hy vọng. Liệu đây có phải là lời giải cho bài toán nan giải của chúng tôi?
Hãy cùng tìm hiểu về Data Catalog trong bài viết này để xem nó có thể giúp chúng tôi giải quyết những khó khăn hiện tại như thế nào nhé!
Nhập môn các thuật ngữ liên quan
Metadata
Nghe có vẻ “cao siêu” nhưng thật ra “em nó” rất gần gũi. Metadata chính là thông tin về dữ liệu trong Data Platform. Ví dụ như thông tin về các table, view, function, pipeline,… Tóm lại, cứ cái gì liên quan đến “mô tả” dữ liệu thì đều là Metadata cả.
Data lineage
Dùng để chỉ dẫn quá trình “biến hình” của dữ liệu, từ “lúc sơ khai” ở source đến “khi thành phẩm” (có thể là table trong Data Mart, hoặc metric trên Dashboard). Hiểu nôm na là “lịch sử hình thành” của dữ liệu.
Data dictionary
Đây là “cuốn từ điển” định nghĩa về dữ liệu và metric được sử dụng trong công ty. Giúp cho mọi người, từ Marketing đến Finance, dễ dàng “nói chuyện” cùng nhau, tránh “ông nói gà bà hiểu vịt”.
Data quality
”Sức khỏe” của dữ liệu, thể hiện qua mức độ chính xác. Dữ liệu “khỏe mạnh” thì mới đưa ra quyết định đúng đắn được.
Và cuối cùng, nhân vật chính của chúng ta: Data Catalog - một “kho lưu trữ” tập trung các Metadata. Như một “Google” thu nhỏ cho dữ liệu vậy!
Các “anh tài” Data Catalog
Vì “team” Tuân đang “chơi” toàn đồ open source và deploy trên “đất nhà” (on-premise), nên Tuân chỉ “điểm danh” các “ứng viên” open source thôi nhé!
Và dưới đây là phần research và tóm tắt của Tuân, chứ cũng chưa có kinh nghiệm trong sử dụng hết những tool này. Bạn nào đã xử dụng và thấy Tuân note không đúng ở đâu thì feedback giúp Tuân nhé!
DataHub
”Ông hoàng” trong làng Data Catalog, “con cưng” của LinkedIn, gánh hơn 10K sao trên Github. “Điểm mạnh” của “anh này”:
- “Cập nhật” Metadata Real-Time (kiến trúc “Event-Driven”)
- “Truy tìm” Lineage tận “cột” (tự động & Real-Time)
- “Tìm kiếm” & “khám phá” “siêu đỉnh” (nhờ AI)
- “Từ điển” & “tag” “chuyên nghiệp” (liên kết tự động)
- “Hợp tác” tốt với các ETL Tools (Airflow, dbt, Spark,…)
- Kết nối “mượt mà” với BI Tool (Looker, Tableau, Power BI)
- Mở rộng dễ dàng (Plugin & API)
OpenMetadata
”Ngôi sao mới nổi” (ra mắt cuối 2021) từ Walmart Labs, “ẵm” hơn 6K sao trên Github. “Tuyệt chiêu” của em nó như sau:
- Hỗ trợ Data Discovery, Data Lineage, Data Governance, Data Observability, Collaboration.
- Lineage tận “cột” (tự động & chi tiết)
- Hỗ trợ tận răng Data Quality & Observability
- Business Glossary & “theo dõi” Metric “từ đầu đến cuối”
- Tương tác tốt với BI & Analytics Tools
- Tích hợp tốt với các ETL Tools & Data Pipelines
- Triển khai đơn giản (Monolithic)
Apache Atlas
”Cây đa cây đề” từ Apache Software Foundation, sở hữu gần 2K sao trên Github. Vũ khí của “bậc tiền bối”:
- Tích hợp tốt với hệ sinh thái Hadoop (HDFS, Hive, Spark, Kafka)
- Lineage đến table level cho các flow Hadoop
Tuân đã chốt deal công cụ nào?
Như Tuân đã trình bày ở trên, mỗi anh tài đều có điểm mạnh, điểm yếu riêng. Quan trọng là mình phải xác định rõ bài toán của mình là gì? Sau đó đi tìm lời giải phù hợp nhất, đơn giản nhất, không cần “hoa hòe, lá hẹ”.
Với problem mà team Tuân đang gặp phải, OpenMetadata có lẽ là “ứng viên” sáng giá nhất, vì các yếu tố sau:
- OpenMetadata setup đơn giản hơn DataHub, mà team mình cũng không cần tính năng real-time của DataHub.
- Data Platform ở công ty Tuân đang làm không xài Hadoop.
- Cuối cùng, OpenMetadata giải quyết được bài toán “traceback” các metric cũng như các pipeline xử lý data liên quan mà team đang đau đầu.
Phần kết
Nhìn lại chặng đường từ Google Sheet đến Wiki.JS, rồi giờ là OpenMetadata, có thể thấy rằng quản lý thông tin dữ liệu không phải là một bài toán tĩnh. Khi Data Platform còn nhỏ, việc tìm kiếm và tổ chức dữ liệu có thể đơn giản, nhưng khi quy mô dữ liệu ngày càng lớn, nhu cầu truy xuất, kiểm soát và đảm bảo chất lượng dữ liệu cũng trở nên phức tạp hơn gấp bội.
Việc lựa chọn công cụ không phải là đi tìm một giải pháp hoàn hảo tuyệt đối, mà là tìm một công cụ phù hợp nhất với nhu cầu thực tế của doanh nghiệp. OpenMetadata có thể là lựa chọn tốt nhất cho team Tuân lúc này, nhưng có thể một ngày nào đó, khi hệ thống mở rộng hơn, DataHub hay một giải pháp khác sẽ lại trở thành ứng cử viên sáng giá.
👉 Dữ liệu không ngừng phát triển, cách chúng ta quản lý nó cũng phải linh hoạt và tiến hóa theo! Nếu bạn cũng đang gặp khó khăn trong việc quản lý dữ liệu, đã đến lúc thử nghiệm một Data Catalog để xem nó có thể giúp ích gì cho đội ngũ của bạn! 🚀